How to create and configure robots.txt file
By: Rajat Kumar | Last Updated: April 15, 2023
Overview:
The robots exclusion standard, also known as the robots exclusion protocol or simply robots.txt, is a standard used by websites to communicate with web crawlers and other web robots. The standard specifies how to inform the web robot about which areas of the website should not be processed or scanned. Robots are often used by search engines to categorize web sites.
Robots Exclusion Standard was developed in 1994 to stop badly-behaved web crawler that causes Denial Of Services attack on servers.
How robots exclusion standard works:
When a site owner wishes to give instructions to web robots they place a text file called robots.txt in the root of the web site server hierarchy (e.g. https://www.example.com/robots.txt). This text file contains the instructions in a specific format (see examples below). Robots that choose to follow the instructions try to fetch this file and read the instructions before fetching any other file from the web site. If this file doesn't exist, web robots assume that the web owner wishes to provide no specific instructions, and crawl the entire site.
This robots.txt file exclusion is different than robots Meta Tags that uses on page level. The main difference between robots.txt file and Robots Meta Tags is that, robots.txt file instruct the search engine crawlers or robots to fetch and index a particular file or directory in web server or not.
On other side robots Meta tags on instruct web crawler to whether page is being indexed or not. But apparently robots Meta Tags cannot controls the page being fetch by web crawler/robots.
Any vulnerability after using robots.txt file:
Yes, surely. Because some of that the rules you define in your robots.txt file cannot be enforced. Crawlers for malicious software and poor search engines might not comply with your rules and index whatever they want. Thankfully, major search engines follow the standard, including Google, Bing, Yahoo, Yandex, Ask, and Baidu.
In this article, I would like to show you how to create a robots.txt file and show you what files and directories you may want to hide from search engines.
How to create and syntax of robots.txt file:
Search engines will look for a robots.txt file at the root of your domain whenever they crawl your website. Please note that a separate robots.txt file will need to be configured for each subdomain and for other protocols such as https://www.example.com.
It does not take long to get a full understanding of the robots exclusion standard, as there are only a few rules to learn. These rules are usually referred to as directives.
The two main of the standard are:
- User-agent – User-agents are search engine robots (or web crawler software). Most user-agents are listed in the Web Robots Database.
- Disallow – Advises a search engine not to crawl and index a file, page, or directory.
Non Standard Robots.txt Rules:
User-agent and Disallow are supported by all crawlers, though a few more directives are available. These are known as nonstandard as they are not supported by all crawlers.
However, in practice, most major search engines support these directives too.
- Allow – Advises a search engine that it can index a file or directory
- Sitemap – Defines the location of your website sitemap
- Crawl-delay – Defines the number of seconds between requests to your server
- Host – Advises the search engine of your preferred domain if you are using mirrors
The syntax for using the keywords is as follows:
User-agent: [the name of the robot the following rule applies to]
Disallow: [the URL path you want to block]
Allow: [the URL path in of a subdirectory, within a blocked parent directory, that you want to unblock]
Examples:
An asterisk (*) can be used as a wildcard with User-agent to refer to all search engines. For example, you could add the following to your website robots.txt file to block search engines from crawling your whole website.
User-agent: *
Disallow: /The above directive is useful if you are developing a new website and do not want search engines to index your incomplete website.
Some websites use the disallow directive without a forward slash to state that a website can be crawled. This allows search engines complete access to your website.
The following code states that all search engines can crawl your website. There is no reason to enter this code on its own in a robots.txt file, as search engines will crawl your website even if you do not define add this code to your robots.txt file. However, it can be used at the end of a robots.txt file to refer to all other user agents.
User-agent: *
Disallow:
URL blocking commands to use in your robots.txt file:
The entire site with a forward slash (/):
Disallow: /A directory and its contents by following the directory name with a forward slash:
Disallow: /sample-directory/A webpage by listing the page after the slash:
Disallow: /private_file.htmlA specific image from Google Images:
User-agent: Googlebot-Image
Disallow: /images/dogs.jpgAll images on your site from Google Images:
User-agent: Googlebot-Image
Disallow: /Files of a specific file type (for example, .gif):
User-agent: Googlebot
Disallow: /*.gif$Pages on your site, but show AdSense ads on those pages, disallow all web crawlers other than Mediapartners-Google. This implementation hides your pages from search results, but the Mediapartners-Google web crawler can still analyse them to decide what ads to show visitors to your site.
User-agent: *
Disallow: /
User-agent: Mediapartners-Google
Allow: /***Note: that directives are case-sensitive. For instance, Disallow: /file.asp would block http://www.example.com/file.asp, but would allow http://www.example.com/File.asp. Googlebot also ignores white-space, and unknown directives in the robots.txt.
Pattern-matching rules to streamline your robots.txt code:
To block any sequence of characters, use an asterisk (*). For instance, the sample code blocks access to all subdirectories that begin with the word "private":
User-agent: Googlebot
Disallow: /private*/To block access to all URLs that include question marks (?). For example, the sample code blocks URLs that begin with your domain name, followed by any string, followed by a question mark, and ending with any string:
User-agent: Googlebot
Disallow: /*?To block any URLs that end in a specific way, use $. For instance, the sample code blocks any URLs that end with .xls:
User-agent: Googlebot
Disallow: /*.xls$To block patterns with the Allow and Disallow directives, see the sample to the right. In this example, a “?” Indicates a session ID. URLs that contain these IDs should typically be blocked from Google to prevent web crawlers from crawling duplicate pages. Meanwhile, if some URLs ending with “?” Are versions of the page that you want to include, you can use the following approach of combining Allow and Disallow directives.
User-agent: *
Allow: /*?$
Disallow: /*?
Non-standard rules syntax:
Sitemap:
A sitemap can be placed anywhere in your sitemap. Generally, website owners list their sitemap at the beginning or near the end of the robots.txt file.
Sitemap: http://www.example.com/sitemap.xmlCrawl Delay:
Some search engines support the crawl delay directive. This allows you to dictate the number of seconds between requests on your server, for a specific user agent
User-agent: teoma
Crawl-delay: 15***Note that Google does not support the crawl delay directive. To change the crawl rate of Google’s spiders, you need to log in to Google Webmaster Tools and click on Site Settings.
Host:
A few search engines, including Google and the Russian search engine Yandex, let you use the host directive. This allows a website with multiple mirrors to define the preferred domain. This is particularly useful for large websites that have set up mirrors to handle large bandwidth requirements due to download and media.
You need to place it at the bottom of your robots.txt file after the crawl delay directive. Remember to do this if you use the directive in your website robots.txt file.
Host: www.mypreferredwebsite.comSave your robots.txt file:
- You must save your robots.txt code as a text file,
- You must place the file in the highest-level directory of your site (or the root of your domain), and
- The robots.txt file must be named robots.txt.
As an example, a robots.txt file saved at the root of example.com, at the URL address http://www.example.com/robots.txt, can be discovered by web crawlers, but a robots.txt file at http://www.example.com/not_root/robots.txt cannot be found by any web crawler.
Testing Your Robots.txt File:
There are a number of ways in which you can test your robots.txt file. One option is to use the robots.txt Tester feature, which can be found under the Crawl section in Google Webmaster Tools.
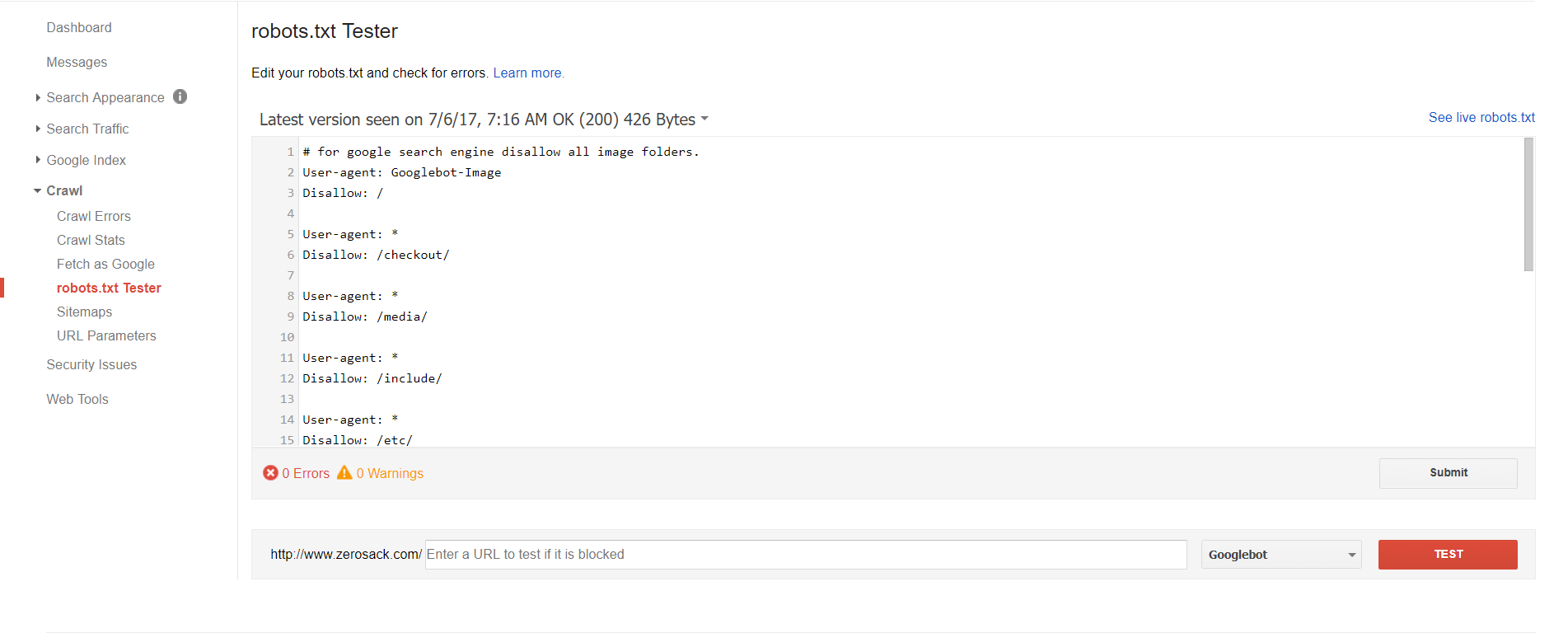
The tool will display the contents of your website’s robots.txt file. The code that is displayed comes from the last copy of robots.txt that Google retrieved from your website. Therefore, if you updated your robots.txt file since then, the current version might not be displayed. Thankfully, you can enter any code you want into the box. This allows you to test new robots.txt rules, though remember that this is only for testing purposes i.e. you still need to update your actual website robots.txt file.
You can test your robots.txt code against any URL you wish. The Googlebot crawler is used to test your robots.txt file by default. However, you can also choose from four other user agents. This includes GoogleMobile, GoogleImage, MediapartnersGoogle (Adsense), and AdsbotGoogle (Adwords).
How to change your Default Timezone in Shared hosting web server Concepts & techniques to find vulnerability and prevent the cyber-attacks (Session-2). Top 10 best SEO techniques must use in website Year 2020 (for beginner). Protecting the Organization Data from Cyber Attacks (Session - 4) Understanding SPF and DKIM for SMTP Email Authentication and How to Configure Them in a DNS Server What is Domain Name Server (DNS) and How Does It Work? Comparing MEAN Stack, MERN Stack, and Full Stack Development: Choosing the Right Technology for Your Project Understanding Nameservers in the DNS System: A Practical Guide with Examples